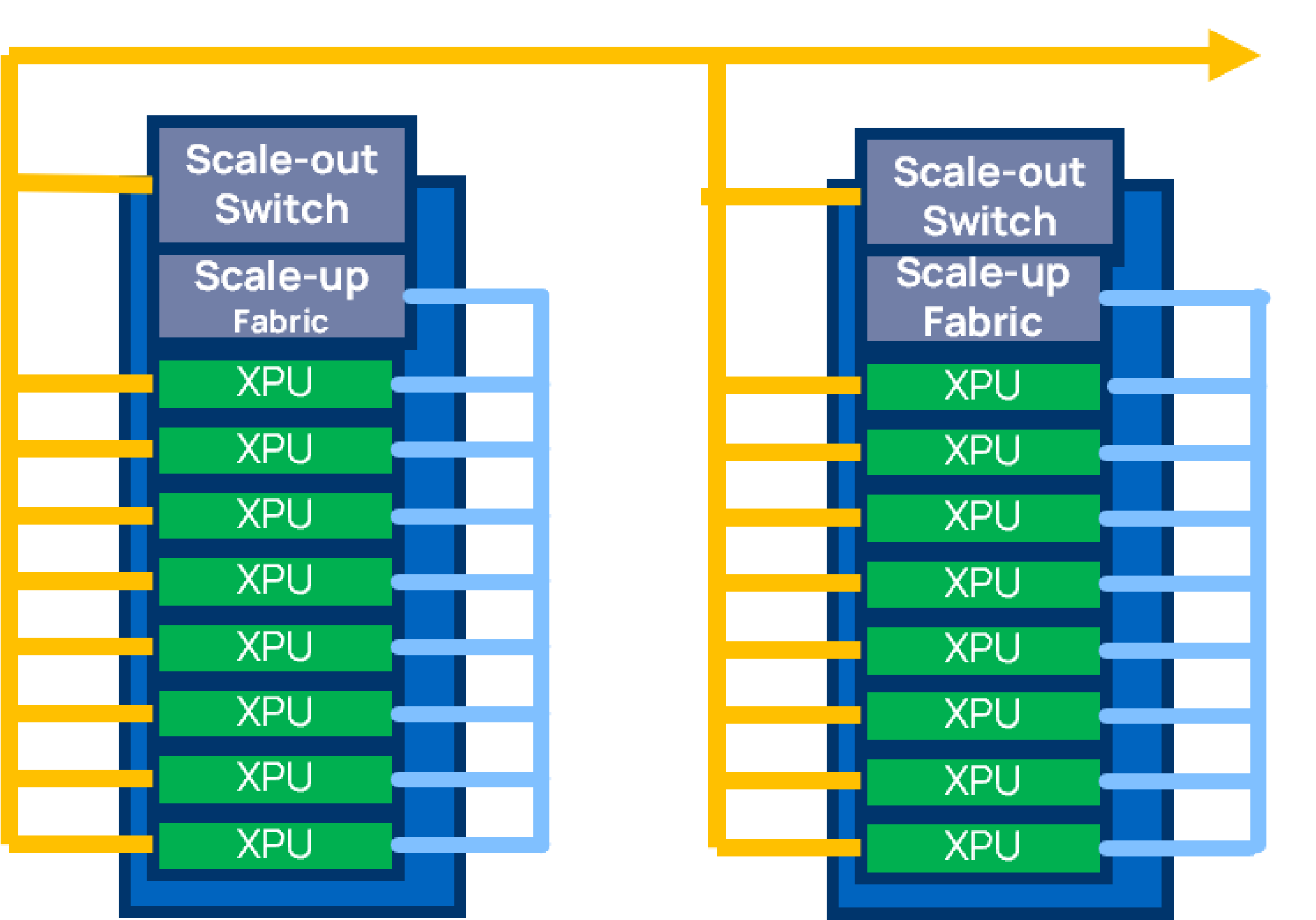
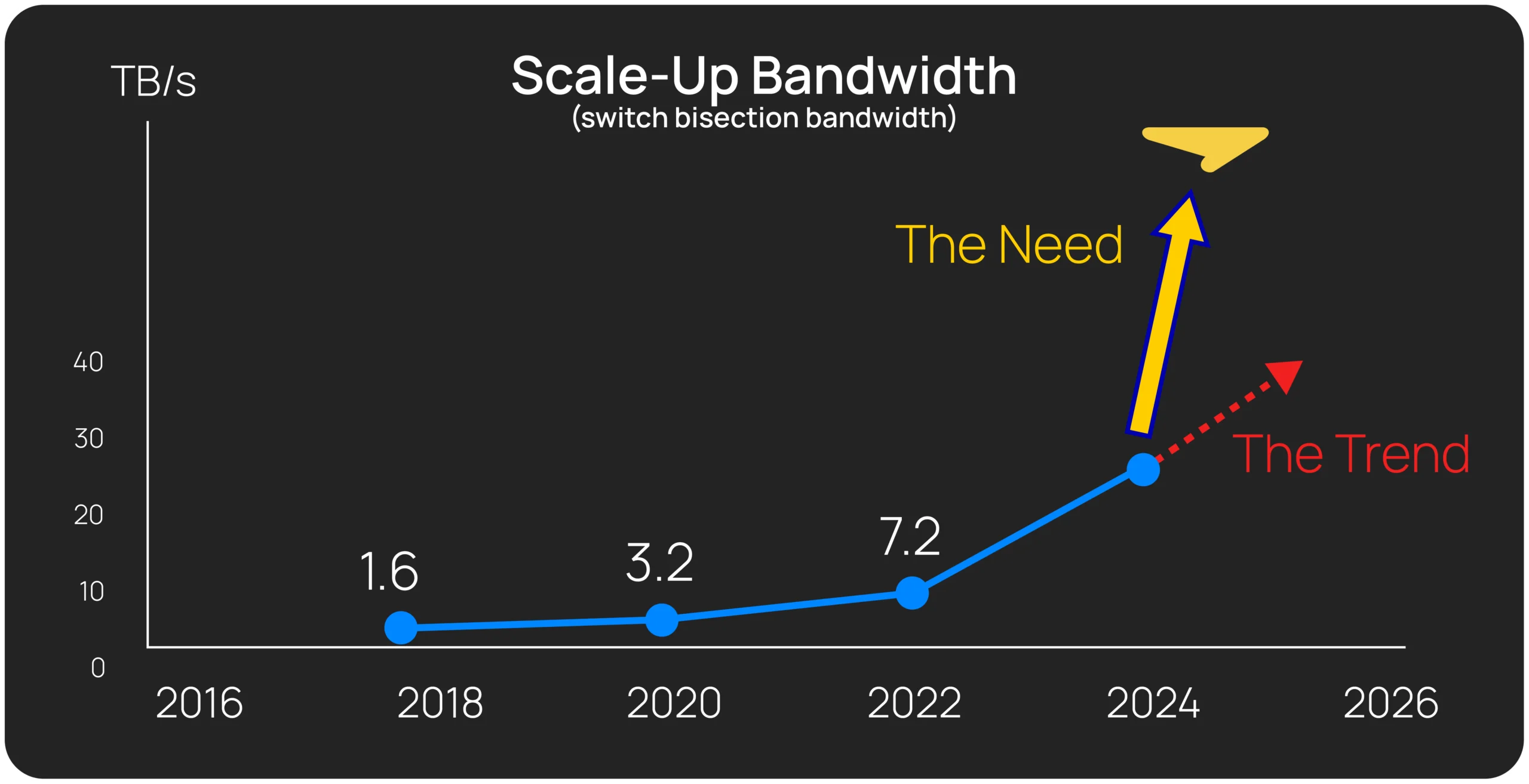
Extreme port density is achieved while maintaining near lowest theoretical latency, tight latency-bandwidth curve and simple physical design with design tiles. While the NeuraScale fabric is optimal for single SoCs, with the emerging 3D chiplet technology, the fabric’s unique chiplet-ready design, the resultant silicon footprint advantage and ease of physical implementation unlock a substantially greater scale than traditional crossbars.