Embracing the Future of Computing: The Era of Unprecedented Data Movement
The computing landscape is evolving rapidly, driven by explosive growth in AI, machine learning, and the need for high-performance computing across various industries, including data centers, automotive, infrastructure, and the edge. As The Wall Street Journal recently noted, “For those who recognize generative AI as an existential opportunity (or threat), new thinking is required: a turnkey AI data center that seamlessly integrates leadership class infrastructure powered by full stack … software that speeds up data movement, access and management across storage, network, and compute.”
Read the full article here.
The demand for greater performance and scalability has never been higher. The semiconductor industries are struggling to keep pace due modern software’s insatiable appetite for compute performance, and the diminishing returns of Moore’s Law. In response, the industry has seen a shift towards custom, heterogeneous, and scalable compute architecture. This allows for on-demand availability of the best combination of compute models tailored to specific workloads, pushing the boundaries of what is possible.
However, at the heart of this evolution lies a critical factor: Data Movement. Much like the connections between neurons in our brains, the ability to efficiently transfer data between compute elements—whether they are CPU and AI engines within a chiplet, chiplets on a package, components on a board, or racks in a data center—ultimately defines the true power and capacity of a computing system. In this new paradigm, the scalability and efficiency of data movement will determine the success of turnkey delivery models and the ability to meet the ever-growing demands of AI-driven applications.
The Data Movement Explosion
At Baya Systems, we are witnessing firsthand, the explosion in data movement in semiconductor designs. Multi-petabyte bisection bandwidth within a package is increasingly common in AI systems, comprising dozens of chiplets with both extreme on- and off-chiplet bandwidth. A single board design can exceed hundreds of petabytes per second in total bandwidth – a scale that was unfathomable just a few years ago.
This surge in data movement is not just about volume; it’s also about diversity in semantics. Traditional System-on-Chip (SoC) designs primarily relied on memory-mapped loads and stores to handle coherent and non-coherent transfers. Today’s designs, however, require a broader set of semantics, including posted unbounded message passing, scatter-gather, broadcasts, and many ordering, switching, buffering and arbitration techniques to optimize efficiency. These evolving needs in chiplet and multi-chiplet design environments are driving a shift towards use of a combination of custom fabric protocols alongside the industry standard ones such as ARM AXI and CHI, Nvidia’s NVLink, Ethernet, and AMD’s Infinity Fabric.
The trend of extreme data movement in scale, bandwidth and diversity shows no signs of abating. In fact, it continues to accelerate. This growth is not limited to AI and cloud; every industry—automotive, infrastructure and edge computing—is being pressured to scale up and adapt.
Challenges in Scaling Performance and the Diversity of Data Movement Semantics
As we advance into the era of heterogeneous computing, one of the most pressing challenges is managing the growing diversity of data movement semantics. Each semantic introduces unique requirements for ordering, consistency, correctness, and performance that can dramatically affect the overall system fabric behavior and complexity. The complexity is further compounded by the need to scale these systems efficiently. For instance, maintaining cache coherency across many chiplets in a multi-chip environment requires intricate protocols that can ensure consistency and correctness without introducing performance bottlenecks. Protocols like ARM’s AMBA and Nvidia’s NVLink are designed to address these challenges but applying them to highly specialized environments and workloads and mixing with custom protocols adds another layer of complexity to each implementation with the tailoring required to achieve the KPI goals.
Each system design requires focus on latency, throughput, and Quality of Service (QoS) requirements to determine how well these data movement semantics are managed. Balancing these factors across a dynamic environment of heterogeneous compute elements such as CPUs, GPUs, NPUs and accelerators, each with its own unique requirements and constraints, can lead to intricate and often unpredictable interactions. The result is a system that is not only difficult to manage but also challenging to program and optimize for peak performance.
The customization needed for each market segment—whether it’s AI, edge computing, or data center applications—introduces further complexity. System architects must continuously fine-tune protocols and pathways to align with specific workload demands, a process that is labor-intensive and prone to errors. Achieving optimal performance across such a diverse set of requirements necessitates a flexible, scalable, and yet precise approach that traditional design and automation tools are ill-equipped to handle.
The Case for Software-Driven Design Approaches from Architecture to In-field Deployment
Given the complexities inherent in modern systems and their data movement needs, there is a clear need for an intelligent, automated and scalable approach to design, implement, and manage these systems. This clearly points to a software-driven approach that can, ideally enable high-level design, performance modelling and implementation. The static, hardware-centric ad-hoc design methodologies of the past are no longer sufficient to address the dynamic, evolving nature of today’s challenges. Instead, the industry must adopt a unified end-to-end system level design methodology powered by a flexible and software-centric framework to drive all phases of the development process.
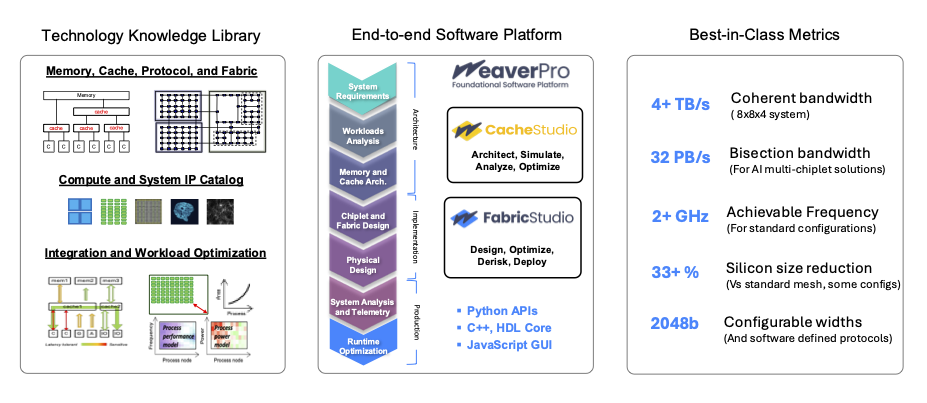
Modular, software-driven design frameworks like the one illustrated above, offer a new way forward. By integrating architecture knowledge, communication protocols, and advanced optimizations, it can become a unified design platform for managing the entire lifecycle of data movement systems. The System architects can first model and simulate a wide range of scenarios, allowing them to converge on robust topologies and organizations that avoid bottlenecks and performance issues long before they imprint on silicon or manifest in the field. With many abstractions, architects can incrementally and programmatically add greater design details—such as describing cache coherency protocol or fine-tuning arbitration policies— at various steps, without being bogged down by the complexity of the entire system or repeating prior work. This granular control on functional abstraction and ability to focus on the problem at hand, is critical in a world where both complexities and time to market pressure are ever growing.
Once the key ingredients and knowledge to design a system is embodied in software, it can be extended and leveraged in field. It can facilitate real-time reconfiguration of data movement hardware and compute elements, ensuring that the system can adapt to new workload deployments and traffic conditions while maintaining performance and correctness. This ability to pivot quickly can be the difference between success and stagnation for turnkey delivery model in dynamic compute infrastructures. By decoupling the architecture from static hardware constraints and connecting them with a software layer to manage the entire silicon lifecycle allows faster innovation with greater precision and an incredible value to end users.
Through these advancements, the industry can move beyond the rigid, monolithic, and disjointed design methodologies of the past and toward a future where 1) data movement is not just a peripheral concern but a central driver of architecture, performance and scalability, and 2) holistic software-driven framework is employed from concept to design to in-field deployment and management, and 3) risk of correctness and time to market pressures are addressed. The challenges of scale, consistency, correctness, and QoS can be met with a level of flexibility, efficiency and sophistication that was previously unattainable.
Looking Ahead: Baya’s Role in Shaping the Future of Data Movement
As we move forward to Intelligent Compute revolution, the role of companies like Baya Systems will make data movement an enabler rather than a bottleneck. Baya is committed to supporting the industry with innovative and scalable data movement technologies built on open standards and protocols. By championing software-driven approaches, Baya aims to enable a seamless design from architecture to implementation to deployment, ensuring that data movement remains efficient, adaptable, and capable of meeting the demands of turnkey delivery models.
As Jensen Huang, CEO of Nvidia, aptly put it, “AI is not just an innovation; it’s a race to build the most performant, efficient, and scalable systems.” This sentiment captures the essence of the ongoing revolution in data movement—a race that requires bold, innovative solutions to keep pace with the rapid evolution of computing.
The future of computing is bright, but it will require a shift in how we think about data movement. Baya’s vision aligns with the industry’s needs, where success is measured not just by raw compute power but by the ability to scale and maintain seamless and efficient movement of data across every node in the system. Through collaboration, open standards, and innovative technologies, we can unlock new levels of performance and efficiency, driving the next wave of computing forward. Baya Systems is committed to being at the forefront of this revolution, helping to shape the architectures of tomorrow and empowering the industry to fully realize the potential of this new era of compute.